Environmental consultants have a quiet data problem.
A single site investigation report may contain borehole logs, groundwater results, soil tables, field notes, laboratory certificates, maps, figures, units, qualifiers, exceedances, and recommendations. Much of that information is trapped inside PDFs. It can be read by people, but it is not always ready for databases, dashboards, trend analysis, or compliance reporting.
That is where AI data extraction is starting to matter.
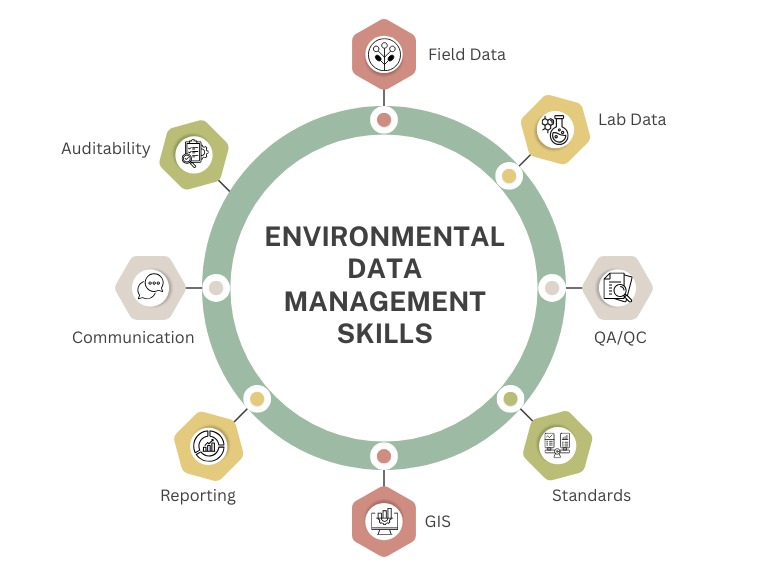
AI is not just “reading PDFs.” At its best, it is helping environmental teams turn old reports into structured, reusable data. That means extracting sample IDs, locations, depths, dates, analytes, units, results, laboratory qualifiers, guideline values, and comments from documents that were never designed for easy reuse.
Key Takeaways
- Environmental PDF reports often contain valuable data that is difficult to reuse in databases or dashboards.
- AI can help extract tables, sample results, borehole data, metadata, and report context from PDF documents.
- The biggest opportunity may be recovering historic data from old reports, not just saving time on new work.
- AI extraction must include validation, traceability, and human review to be reliable for environmental work.
- EScIS has discussed AI-assisted PDF data extraction and is developing tools embedded into ESdat to guide this process.
Why PDF reports are such a difficult data source
PDFs are excellent for sharing finished reports. They are poor for managing data.
Environmental reports are especially difficult because they often combine:
- scanned pages
- text-based pages
- tables split across pages
- laboratory certificates
- maps and figures
- footnotes and qualifiers
- inconsistent units
- different naming conventions
- historic formats from different consultants and laboratories
Traditional optical character recognition can extract text, but it often loses context. A result without the correct sample ID, unit, depth, or date is not reliable data. In environmental work, this matters because a small transcription error can affect compliance decisions, remediation planning, risk assessment, or reporting to regulators.
What AI changes
Modern AI can combine several tasks that used to be separate:
- It can read text from a PDF.
- It can understand document layout.
- It can identify tables.
- It can classify sections of a report.
- It can extract values into a structured format.
- It can compare extracted data against expected fields.
- It can flag uncertain results for human review.
This is important because environmental data extraction is rarely a simple “copy table to spreadsheet” task. The system needs to understand that “BH03 1.0–1.5 m”, “Borehole 3 at 1.0 to 1.5 metres”, and “BH-3_1.0-1.5” may refer to the same sampling interval.
What EScIS is doing with AI extraction
EScIS, the company behind ESdat Environmental Data Management Software, has discussed AI for data extraction from PDF reports in its MyGeoWorld article, “AI for Environmental Data Extraction from PDF Reports”. The main point is practical: many environmental datasets are locked in legacy PDF reports, and AI can help guide the process of extracting that information for reuse.
EScIS has also publicly stated that it is developing tools embedded into ESdat to guide users through AI-assisted PDF data extraction. This is an important distinction. The goal is not simply to use AI as a generic chatbot. The more useful approach is to place AI inside an environmental data management workflow, where extracted data can be checked, structured, validated, and used.
That matters because environmental professionals do not just need “answers.” They need defensible data.
The most overlooked benefit: recovering historic data
Most AI discussions focus on speed. Speed matters, but it may not be the biggest benefit.
The bigger opportunity is historic data recovery.
Environmental projects often have years or decades of old reports. These reports may contain useful groundwater trends, contaminant changes, borehole logs, soil chemistry, vapour data, or remediation evidence. But if that data remains in PDFs, it is difficult to compare across time.
AI extraction can help turn historic reports into datasets that can be searched, mapped, graphed, and compared.
This could support:
- trend analysis
- plume assessment
- baseline reconstruction
- due diligence
- contaminated land audits
- regulatory reporting
- data migration into environmental data management systems
- better reuse of past investigations
In other words, AI may help companies find value in information they already paid to collect.
Interesting statistics people are not discussing enough
A common estimate is that around 80% of global data is unstructured. PDFs, images, reports, emails, photos, and scanned documents are part of that problem. Yet many environmental data systems still depend heavily on structured tables, spreadsheets, and databases.
Another under-discussed point is that document AI is becoming a major software category. One market estimate projects the Document AI market to grow from US$14.66 billion in 2025 to US$27.62 billion by 2030. That growth is not just about invoices and legal contracts. It reflects a wider shift toward extracting structured data from documents at scale.
There are also cautionary numbers. Research on ESG report extraction found that GPT-4 achieved 76.9% accuracy for data extraction and 83.7% accuracy for disclosure analysis in one tested framework. That is impressive, but it is not “set and forget.” In environmental work, 76.9% accuracy is not enough without review, validation, and traceability.
This is why the future is not fully automated extraction. It is AI-assisted extraction with human review.
Why environmental PDF extraction is harder than general PDF extraction
Environmental reports are not like invoices.
An invoice usually has predictable fields: supplier, date, amount, tax, and invoice number. An environmental report may include hundreds of analytes, multiple sampling events, different matrices, different units, and complicated qualifiers.
For example, a groundwater result may need:
- sample location
- sample date
- matrix
- analyte name
- result value
- unit
- detection limit
- laboratory qualifier
- field duplicate relationship
- depth or screen interval
- regulatory standard
- exceedance status
If any one of these is separated from the others, the extracted data may be misleading.
This is why environmental AI tools need domain knowledge. A general PDF extraction tool may identify a table. A better environmental system also understands why that table matters.
The importance of traceability
For environmental consultants, traceability is essential.
Every extracted value should be linked back to its source. Users should be able to click from a database record back to the page, table, row, or certificate where the value came from.
This is important for three reasons.
First, it builds trust. Users are more likely to accept AI-assisted extraction when they can inspect the source.
Second, it supports quality assurance. A reviewer can check uncertain or high-risk values instead of reviewing every value from scratch.
Third, it helps with defensibility. Environmental decisions may be audited, challenged, or revisited years later.
The strongest AI extraction workflows will not hide uncertainty. They will show it.
AI should not replace validation
AI can extract data, but validation still matters.
Environmental data needs checks such as:
- are units consistent?
- are analyte names standardized?
- are sample dates valid?
- are duplicate samples linked correctly?
- are results below detection handled properly?
- are qualifiers preserved?
- are coordinates plausible?
- are regulatory standards applied correctly?
- are exceedances calculated using the right matrix and jurisdiction?
This is where AI extraction should connect with environmental data management software. Extraction is only the first step. The real value comes when extracted information enters a controlled workflow.
The best workflow: AI plus rules plus people
A practical workflow might look like this:
- Upload the PDF report.
- AI classifies the document sections.
- AI extracts tables, locations, sample data, lab results, and metadata.
- The system maps extracted fields to a standard data structure.
- Validation rules check units, analytes, dates, locations, and qualifiers.
- The user reviews uncertain or high-risk values.
- Approved data is imported into the environmental database.
- The original PDF remains linked for audit and traceability.
This is a better model than asking AI to “read the report and give me the data.” Environmental work needs a controlled chain from source document to verified dataset.
Where AI extraction can help first
The best early use cases are not always the most complex. Environmental teams should start where there is high manual effort and clear review logic.
Good starting points include:
- extracting laboratory result tables
- digitising borehole logs
- pulling groundwater monitoring data from old reports
- extracting sample locations and depths
- converting historic tables into database-ready formats
- identifying exceedance tables
- summarising report metadata
- locating where key contaminants are discussed
The aim should be to reduce repetitive work, not remove professional judgment.
The risks to manage
AI extraction can fail in subtle ways.
It may:
- misread decimal points
- confuse units
- merge table rows incorrectly
- ignore footnotes
- miss non-detect qualifiers
- invent a value when a cell is blank
- lose the relationship between a result and its sample ID
- extract a number without its context
- treat a screening value as a measured result
These errors are manageable if the system is designed for review. They are dangerous if the output is accepted blindly.
What good AI extraction should include
A serious AI extraction system for environmental PDF reports should include:
- source-page references
- confidence scoring
- structured output
- human review screens
- unit standardisation
- analyte name matching
- duplicate detection
- validation rules
- audit history
- export to common environmental data formats
- integration with environmental data management software
The most useful tools will not simply produce a spreadsheet. They will produce reviewable, traceable, database-ready data.
The future: from static reports to living datasets
Environmental reporting has traditionally ended with a PDF. AI may change that.
In the future, a report may still be delivered as a PDF, but its data will not remain trapped there. It will be extracted, validated, linked, mapped, and reused. Old reports may become part of live datasets. Historic monitoring results may feed trend analysis. Borehole logs may become searchable. Laboratory tables may be compared across projects.
This does not make environmental professionals less important. It makes their time more valuable.
Instead of manually copying data from PDFs, consultants can spend more time asking better questions:
- Is the plume stable?
- Are concentrations declining?
- Are standards being exceeded?
- Is the conceptual site model still valid?
- What data gaps remain?
- What should happen next?
Glossary
- AI data extraction
- The use of artificial intelligence to identify and extract useful information from documents, images, tables, or reports.
- Environmental data management system
- Software used to store, validate, analyse, map, and report environmental data such as soil, groundwater, surface water, air, and field observations.
- PDF report
- A fixed-format document commonly used to share environmental reports, laboratory certificates, figures, and appendices.
- OCR
- Optical character recognition. A technology that converts text in scanned images or PDFs into machine-readable text.
- Structured data
- Data organised into defined fields, rows, columns, or database tables.
- Unstructured data
- Information that is not stored in a fixed database format, such as PDFs, reports, emails, images, and scanned documents.
- Traceability
- The ability to link a data value back to its original source, such as a page, table, row, laboratory certificate, or report section.
- Validation
- The process of checking data for accuracy, consistency, completeness, and suitability before it is used.
- Qualifier
- A note or code attached to a laboratory result that explains how the result should be interpreted.
- Non-detect
- A result showing that a substance was not detected above the laboratory reporting limit.
FAQs
What is AI data extraction from PDF reports?
AI data extraction from PDF reports is the use of artificial intelligence to pull useful information from PDF documents and convert it into structured data. In environmental work, this may include sample IDs, laboratory results, borehole logs, locations, dates, units, qualifiers, and exceedance information.
Why are environmental PDF reports hard to extract data from?
Environmental PDF reports are difficult because they often include scanned pages, complex tables, laboratory certificates, maps, footnotes, inconsistent naming conventions, and data spread across many pages. A result is only useful if it stays connected to the correct sample, location, unit, date, and context.
Can AI replace manual environmental data entry?
AI can reduce manual data entry, but it should not fully replace review and validation. Environmental data often supports compliance, remediation, and risk decisions, so extracted data should be checked before it is used.
What is the main benefit of AI extraction for environmental consultants?
The main benefit is not only faster data entry. AI can also help recover historic data from old PDF reports, making it possible to search, analyse, map, and compare information that was previously difficult to reuse.
What is EScIS doing in relation to AI PDF data extraction?
EScIS has discussed AI for environmental data extraction from PDF reports and has stated that it is developing tools embedded into ESdat to guide users through AI-assisted PDF data extraction. This suggests a workflow-based approach, where extracted data can be structured, checked, and used in environmental data management.
Why is traceability important in AI data extraction?
Traceability allows users to link an extracted value back to the original PDF page, table, row, or laboratory certificate. This helps reviewers check the data and supports defensible environmental reporting.
What types of environmental data can AI extract from PDF reports?
AI may help extract laboratory result tables, groundwater monitoring data, borehole logs, sample depths, sample dates, locations, exceedance tables, analyte names, units, qualifiers, and report metadata.
What are the risks of using AI for PDF data extraction?
AI may misread decimal points, confuse units, merge table rows, miss footnotes, lose sample relationships, or extract numbers without context. These risks can be reduced through validation rules, confidence scoring, source references, and human review.
Should AI extraction connect to environmental data management software?
Yes. AI extraction is most useful when it connects to a controlled environmental data management workflow. That allows extracted information to be checked, standardised, validated, stored, analysed, and reported.
Is AI extraction suitable for historic environmental reports?
Yes, historic reports may be one of the strongest use cases. Many organisations have years or decades of environmental information stored in PDFs. AI can help recover that data and make it usable for trend analysis, due diligence, compliance reporting, and site understanding.
Conclusion
AI for environmental data extraction from PDF reports is not a magic button. It is a practical tool for a long-standing problem.
The opportunity is clear: environmental organisations have large amounts of valuable data locked inside reports. AI can help recover that data, but only when it is paired with validation, traceability, and environmental domain knowledge.
That is why the work being discussed by EScIS and ESdat is worth watching. The most valuable AI tools in this space will not be generic PDF readers. They will be tools built into real environmental data workflows, where extracted data can be checked, trusted, and used.